
Optimize digital experiences & maximize conversions
Your customer is evolving every day. Decode their evolving behaviors, fine-tune with robust experimentation, and personalize experiences that hit home. Boost conversions across your websites and mobile apps through data-driven UI and server-side enhancements.
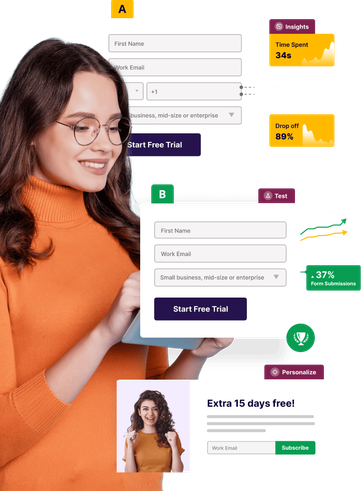
Thousands of businesses use VWO to analyze, optimize, and personalize their websites, apps, and features.


Comprehensive Experimentation Platform
End-to-end optimization of entire digital user journeys to deliver exactly what your customers want.
My business needs:
Fueled by robust customer data platform
VWO's agile, event-driven architecture seamlessly blends with your websites, apps, and code bases, offering a holistic 360-degree view of your customer. Make instant decisions with real-time customer data at your fingertips. Get insights from unified data provided by VWO and other platforms you use to deliver delightful experiences.

Powered by VWO’s cutting-edge tech
Experience lightning-fast optimization, driven by our dynamic CDN technology and the robust Google Cloud Platform (GCP). VWO is engineered to minimize payloads, improve latency, and compute only what's crucial for your campaigns. Ensure precise results with unrivaled speed, leveraging GCP's secure and scalable infrastructure.
Build your optimization program across all teams
An impactful optimization program extends across teams and benefits the whole organization. Our platform is designed to empower all teams by solving problems specific to them.
Product Managers
-
 Optimize to make sticky apps and features.
Optimize to make sticky apps and features. -
Test complex server-side functionalities.
-
Measure the engagement, adoption, loyalty, and conversion of your product users.


I really like that we can use VWO across every department. It's user-friendly, straightforward, and test results are easily comprehensible even for non-testing individuals.
Senior Product Manager


Engineers
-
Ship features with confidence.
-
Reduce risk with the progressive deployment of features.
-
Use easy-to-configure SDKs.
-
Get an SDK for every stack & device.

With VWO, we have executed and implemented numerous A/B tests that have helped improve overall CRO architecture across our website.
Web Developer



Growth Marketers
-
Create and optimize omnichannel experiences that are hyper-targeted to user personas.
-
Track CTR, AOV, and forms filled for your visitors.
-
Test and personalize without going to your developer.

Using VWO, we are able to swiftly launch A/B tests, tackle data trends and customer problems. We merge VWO reports with our tools for complete insights into user behavior.
Sr. Director, Site Content & Creative Operations



UX & Analytics
-
Identify roadblocks in the buying journey.
-
Rectify bottlenecks by testing images, layouts, and placements.
-
Test to build low friction scroll experience.

VWO helps us get real results with tangible insights for our clients. Flexibility to set up as many goals on the fly is incredibly valuable to get the most out of an experiment.
Director, User Experience



Deliver experiences that your users love
VWO products empower you to create and rollout great digital experiences using a suite of products built for your entire optimization program for any application. Understand user behavior with qualitative insights. Validate your optimization hypothesis with testing. Know what works for a specific audience. Personalize it at the right place, right time. All using one platform.
Create wow experiences using your user data
Observe user behavior and events, and track key attributes to understand how your customer behavior is evolving. So that you can evolve your digital experiences as per your user’s expectations. You can also use this data to build effective hypotheses for testing. And to optimize any visitor data segment, whether from your application, third-party sources, or offline data.
User Attributes

User Events

Third Party Data
Offline Data

Optimize what matters to you
Optimize experiences on any device. Track and understand your user behavior on websites and mobile apps. Use this customer data to test and personalize UX, content, feature variables, server-side functionality, or any complex use case.
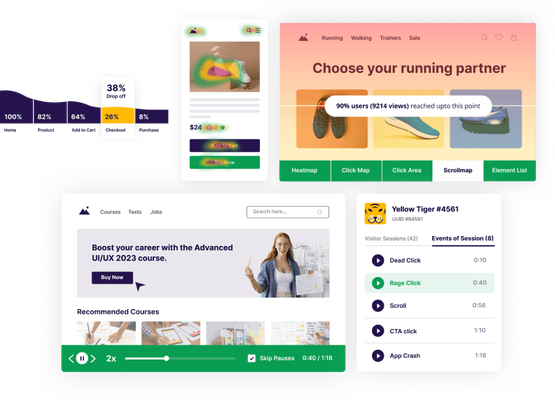
Pin down friction areas by observing user behavior
Take a closer look at digital user journeys and identify conversion roadblocks using heatmaps, session recordings, funnels, form analytics, and surveys.
-
 Discover growth opportunities in your website and mobile app
Discover growth opportunities in your website and mobile app -
Observe to generate informed ideas and hypotheses to test
-
See how visitors engage with your test campaigns
Make AI a co-pilot to your campaigns
Set up your optimization campaigns in a flash by leveraging generative AI at every step of your optimization journey in VWO.
-
Generate survey questions and summarize survey reports in minutes with AI
-
Get highly specific AI-generated optimization ideas for your website
-
Instantly get copy variations powered by GPT-4 Turbo and test them

Build experiences using high-performance script and SDKs
Start testing without breaking a sweat. We are easy to configure and get started.
Web Script
VWO SmartCode powers your entire experimentation cycle singlehandedly. It also has the least impact on Total Blocking Time (TBT) on your website and offers the best performance in the industry.

SDK and APIs
VWO’s secure, lightweight SDKs in 8+ languages enable you to run complex back-end tests while ensuring that your visitors have a seamless experience across devices even when they are part of a test. You can also track their on-app behavior using our mobile insights SDK.
Run unlimited optimization at scale
Optimize as much as you want, with no limit on variations, account users, metrics, session recordings, or integrations to your user data source.
Users
Concurrent
campaigns

Session
recordings

Integrations
Metrics

Test everything under one roof
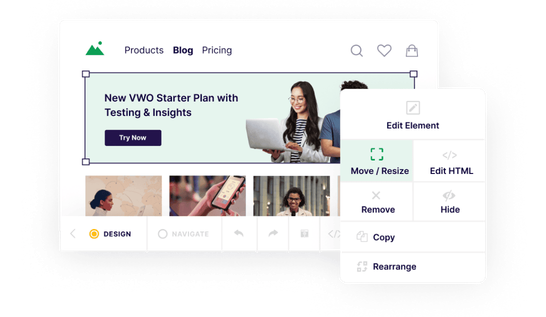
Whether you have a website or mobile app, we provide SDK-based testing for all technologies. For non-techies, our powerful, no-code visual editor is all you need to get started with testing (without any engineering support).
Visual Editor
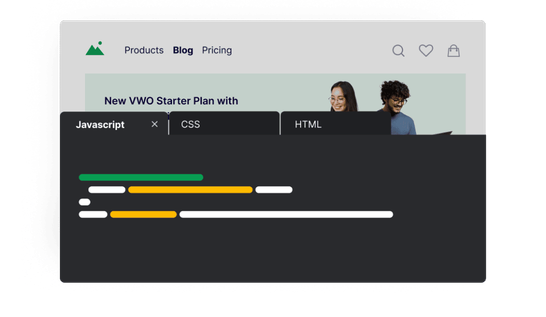
Code Editor
SDK-based Testing

Identify changes that boost your key metrics
Did an experiment unexpectedly impact conversions or customer behavior? Use VWO’s accurate, real-time reporting using Bayesian Statistics to discover it easily. VWO's reports help you answer business questions by giving you insights into whether your variations are better than control, equivalent to control, or worse than control.

Over a decade of experience in optimization
Zero compromises on privacy, security, and compliance
At VWO, we take a privacy-first approach to building world-class products.






Designed to be enterprise-ready and scalable
VWO Platform has everything large businesses need: top-notch features, strong security, easy accessibility, and excellent performance.
Experimentation Loop
In this ebook, we show you how to structure your experiments into a simple three-steps loop that will help shape customer experience in a positive direction at your company. And to top it off, we provide real-world examples of brands that have successfully used experimentation loops to achieve impressive growth.
Get a Copy Now










